作者丨Tau
这是CVPR2023的一篇姿态估计相关的工作,但是严格来说,本文提出的技术是在其他领域也通用的,作者仅仅是在姿态估计任务上验证了其有效性。

通过上图可以看到,在该技术的加持下,ResNet152、HRNet32、HRNet48均有5个点以上的提升,其中HRNet48在COCOtest-dev上的精度从75.5AP来到了80.6AP,这种提升是非常恐怖的。要知道,姿态估计领域在COCO上的指标已经非常高了。
需要声明的是,本工作并没有开源,因而有效性有待检验,笔者在这里主要是觉得本文的思路很新颖,因此分享一下。
论文标题:Self-CorrectableandAdaptableInferenceforGeneralizableHumanPoseEstimation
论文地址:
一边推理一边训练?本文的核心直接体现在标题中,提出了一种称为“可以自修正和自适应的推理方法”(Self-correctableandadaptableinference,SCAI)。之前的所有工作与技术,在推理时,模型参数都是冻结的。本文的有趣之处在于,提出了一种修正网络,能在完全没有标注的测试样本上进行训练,逐步修正预测结果,带来显著的性能提升。
如果让我对这种技术进行归类,我倾向于它属于一种Test-TimeAugmentation(TTA),因为事实上,本文完全没有去训练姿态估计网络,而是在训练好的姿态模型后面增加了一组修正模型,来对预测结果进行修正,从而取得更好的结果,这与我们常见的Flip-test、Multi-scale等TTA技术是异曲同工的。
TTA技术的好处在于,完全不依赖标注数据,是一种可以直接在测试时提升模型精度的技术,姿态估计中大家往往会默认使用Flip-test,即,除了输入图片本身的预测结果外,还会将图片进行一次水平翻转,用翻转后的图片推理一次,再把结果水平翻转回来,两次推理的结果取平均。这样简单的两次推理,普遍能为模型带来1-2个点的精度提升。
而TTA的坏处也很明显,就是增加了额外的推理和计算量,而且往往开销都不低,因此这并不是一种应用在实时推理中的技术,更多地用在比赛、刷榜、机器标注等对实时性要求不高的场景。
三个网络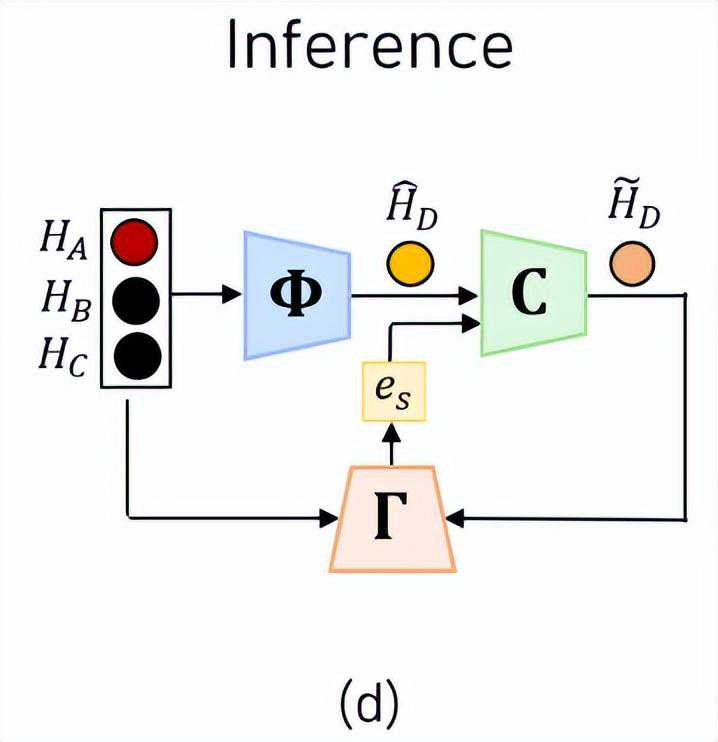
那么,在测试样本上进行训练是如何做到的呢?这里我们直接放出SCAI的流程图。SCAI中一共包含了三个需要训练的网络,并且需要特别提示的是,我们通常的姿态估计网络并不在这里面,SCAI方法的输入直接是姿态模型预测的Heatmap。
预测网络预测网络的输入是一组关节点Heatmap,输出是与之相关联的下一个关节点。更具体地讲,预测的是远端关节点,也就是手腕点、脚踝点这种位于肢体最外侧的节点,这些关节点往往具有最大的自由度,作者在误差分析中也发现大部分的预测误差来自于对这些远端关节点的预测。
为了简化问题,作者手工将人体关节点分成了6组,从而使得每一组的关节点都是一条直链。
经过分组后,每一组都正好只有4个节点,即有一个近端关节点、一个远端关节点,和两个中间节点。我们将近端关节点的Heatmap称为,远端关节点称为,两个中间节点分别为。
预测网络的工作就是输入,来预测远端关节点的位置,记为。
修正网络通过这两个输入,修正网络会预测一个修正的偏移量,这个偏移量可以直接加到原来的上完成修正,修正后的远端关节点记为:
这里作者团队的设计非常巧妙,依然是利用了之前的直链分组推理。既然预测网络可以通过节点ABC来预测D,那么反过来通过BCD我们是不是也应该可以预测A?
因此,这里直接为与之差的二范数:
也可以表示成:
如此一来,三个网络各自的输入输出关系就捋清楚了:
由于本工作中用到的符号较多,大家可以多对照图片在脑中过一下流程。
如何训练?介绍完三个网络后,让我们来看一下网络是怎么训练的。很明显,这三个网络的能力都不是与生俱来的,同样需要在标注数据上进行训练才能获得。
对于预测网络,训练损失就是预测的与GT的误差二范数:
这两个网络某种程度上来说推理过程是对称的,因此损失函数的设计也比较一致,最复杂的要数修正网络了损失函数了,它长这个样子:
先别着急,虽然看起来符号很多,但实际上里面有很多我们已经知道的量,仅仅是换了个符号。
这个损失函数由三个损失组成,我给它们各自起了个名字方便理解,分别是:
可以发现,这里又出现了一个新的符号,它代表的是用修正之前的旧的和预测出来的近端关节点。
我们知道,唯一的区别在于,一个使用的是修正后的D,一个是修正前的D,如果经过修正网络后的D是更好的,那么自然而然损失值就会更小,因而为负,损失值降低,因而促进修正网络的训练。
整个训练阶段,所有网络的损失值产生关系如下:
如何推理?推理阶段,三个网络共同组成了一个TTA,在测试时提升预测的精度。如果整个工作到此为止的话,只能说是一个还不错的工作,相当于又训练了一套模型用于后处理时的结果refine。
但是本文最有意思的地方在于,这个修正网络并不仅仅在有标注的数据上可以训练,还能在无标注的测试数据上继续训练。
很自然地疑问会是,没有了标注信息,损失如何计算呢?
在生成对抗网络中,训练好的判别器可以对生成图片的质量进行评估,如果把输入输出的Heatmap看成是图片的话,预测网络和修正网络实际上干的是生成器的活。只不过,GAN中我们想要的是那个生成器,判别器只是工具人,训练完就扔掉了。
在SCAI推理阶段,将训练好的判别器进行冻结,它就可以充当损失函数的角色来训练修正网络了,从某种意义上来说,这也算是一种自监督了。
实验结果这里列一些我觉得有意思的实验结果。
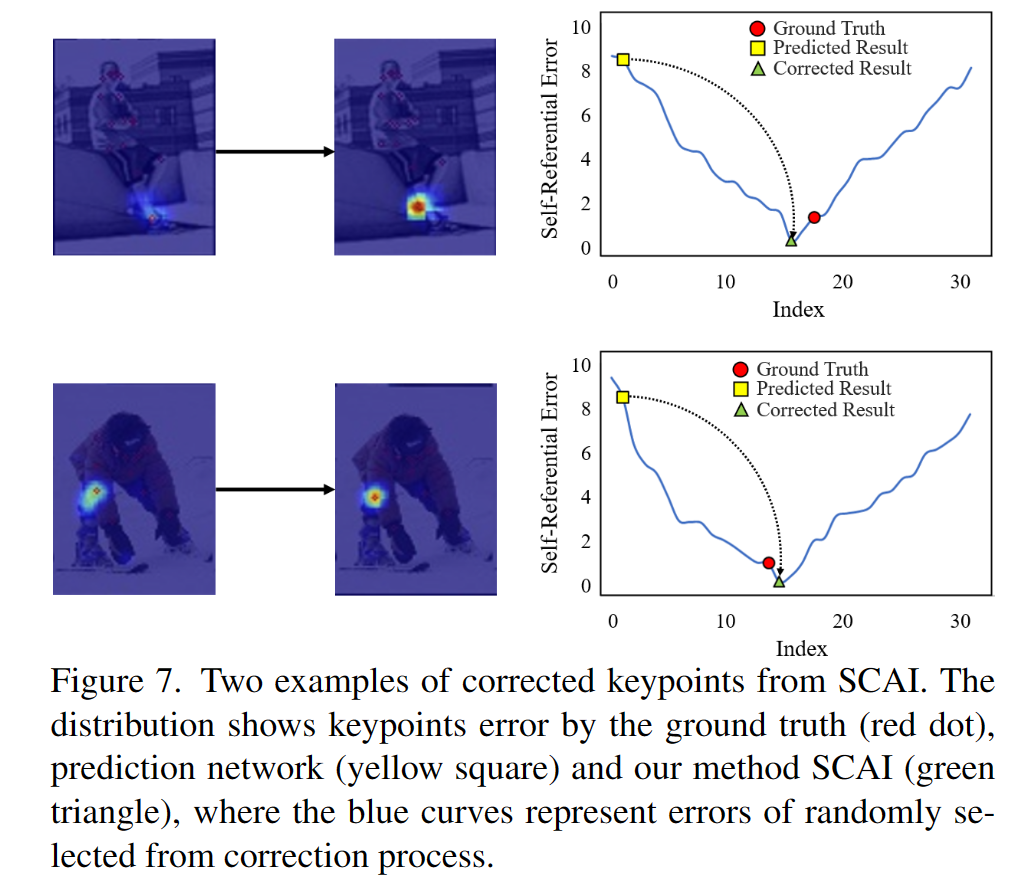
消融实验可以看到,即使没有自参照误差,单独的修正网络也能带来3个点的提升。加入误差修正网络联合训练后带来了1.3个点的提升,而加入推理时训练,则又能产生0.8AP的收益。
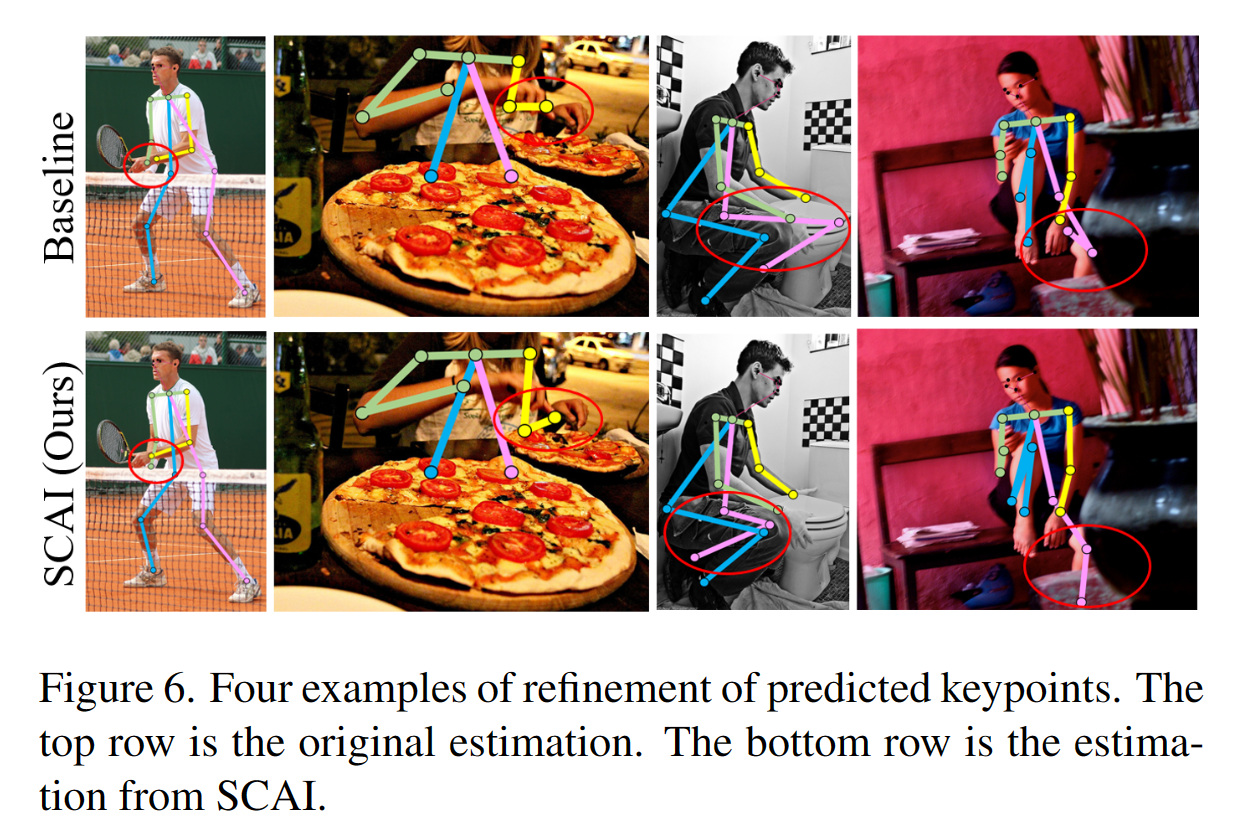
一些修正结果可视化:
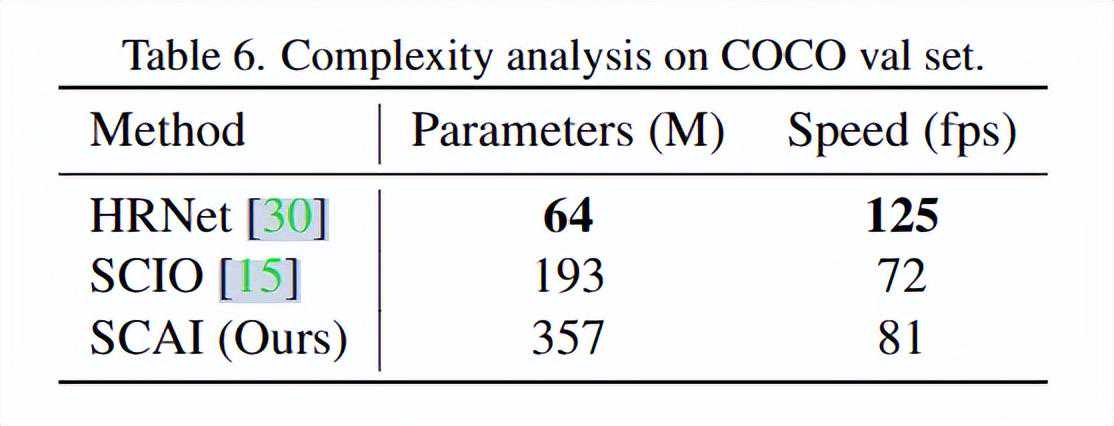
复杂度分析的部分就可以发现,这个方法是相当的不便宜,比起单独的HRNet参数量翻了接近6倍。
结语本文提出了一种自适应自监督的推理方法,能在完全没有标注的测试样本上进行训练,逐步修正预测结果,带来显著的性能提升。
其背后的思想透露出了GAN的影子,对人体结构进行分组成直链,然后推理远端节点也隐隐约约让我有种时序建模的感觉,让我一瞬间联想到曾爱玲博士的几篇相关工作,比如我介绍过的SmoothNet和用简单LinearLayer超越Transformer的工作AreTransformersEffectiveforTimeSeriesForecasting?
说到底,这种修正和误差判别,真的需要用Heatmap这种高计算复杂度的位置表征作为输入输出么?用一条直链上高置信度的点的结构,去预测下一个点位置,这跟MaskedModeling的思想也是相似的,甚至简单得多。上一篇我介绍过的PCT只使用坐标值同样可以学习姿态结构特征空间,或许SCAI方法也可以简化到使用两层MLP完成修正,那在实时推理场景就大有可为了,有兴趣做这个research探索的小伙伴也许可以联系我一起讨论交流。